Bagging 이란 무엇인가
Decision tree 한 개의 성능보다 이 Decision tree들을 여러개 모아 결론을 종합하는 Bagging, Random Forest, Boosting 방법이 훨씬 성능이 좋다. 이 글에서는 이 3가지 방법들 중 Bagging에 대해 우선 알아보고자 한다.
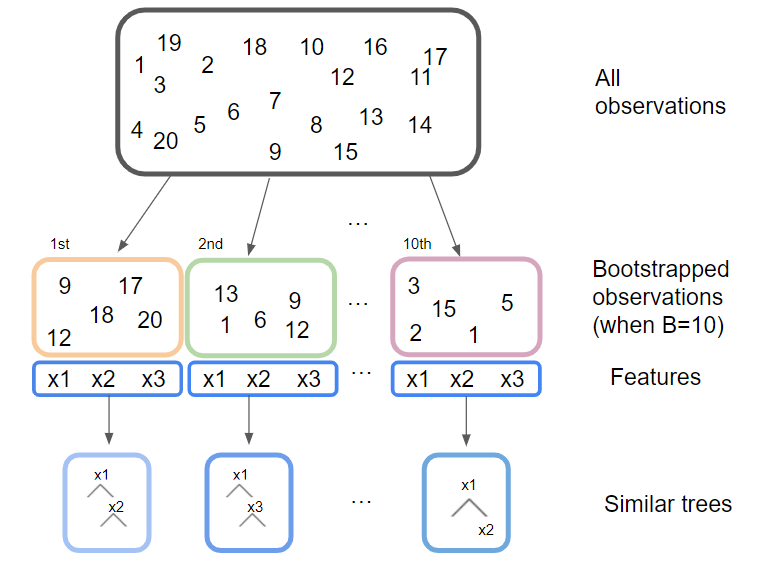
Bagging은 Bootstrap aggregation이라고도 불리는 데 통계적 학습 방법의 variance를 줄이기 위해 일반적으로 사용되는 방법이다. 참고로 Bootstrap 의 맨 앞글자 B, Aggregation 의 앞 두글자인 ag 가 합쳐져서 Bagging 이라고 한다. Variance를 줄이는 원리는 간단하다. 우리가 Standard Error of Mean을 계산 할 때에도 population으로부터 variance 가 sigma squared 인 독립적인 sample 을 계속 해서 추출하면 그 sample들의 평균값들이 계산되는데 그 sample 들의 평균의 variance는 sigma squared가 아니라 sigma squared 를 n만큼 나눠준 분량이 된다. 즉, n 수 만큼 variance가 더 줄어드는 원리라고 할 수 있다. 예를 들어 10개의 bootstrap 된 training dataset 이 있다면 1번부터 10번까지의 training set이 생기게 되며 그 training set 마다 tree를 fitting 하고 예측된 결과의 평균을 계산한다. 이렇게 하면 확실히 variance 는 줄어든다.
Bagging 의 OOB를 대상으로 예측하는 방법
이런 bagging 방법을 regression 에 적용할 경우 예측 대상은 연속된 숫자이므로 예측값끼리 평균을계산하여 여러 tree들의 결론을 종합하라 수 있다. 만약 예측 대상의 값이 categorical 한 값인 경우 (예를 들어 a 라는 class와 b라는 class) 이들 끼리 더하거나 나눌 수도 없어 평균을 계산할 수 없다. 이런 경우에는 다수결의 원칙을 따른다. 만약 10개의 bootstrapped 된 training dataset 이 있고 그 중 9개는 class a 라는 예측값을 내놓고 1개만 class b라는 예측값을 내놨다고 가정하면 다수결의 원칙을 따라 a 라는 결론을 얻을 수 있게 된다.
Bagging을 하고 나면 test error 를 예측하는게 굉장히 쉬워진다. 복원추출에서 사용된 observation은 전체 observation 중의 70% 정도를 차지한다. 그렇게 되면 나머지 사용되지 않은 관측값은 자연스럽게 30% 정도의 비율이 되며 이들을 OOB (Out of bag) observation 이라고 부른다. 그리고 이것을 사실상 test dataset 인것으로 취급한다. 즉, 따로 training dataset, test dataset을 나누지 않아도 되는 것이다. 구체으로 설명하자면, i번째 관측치의 response variable의 값을 예측할 때에는 그 관측값이 OOB 에 해당하는 경우의 값을 통합하여 예측한다. 예를들어, Bootstrap을 9번 했다고 하면, B =9 이다. 그럴 경우 1번째 관측치가 OOB 에 해당하는 경우는 B를 3으로 나눈 값(9/3) 인 3이 된다. 그러면 이 3경우에서의 예측값이 다 다르게 나올 수도 있는데, 이것을 regression 의 경우 평균을 내거나 classification의 경우 다수결의 원칙을 따라 가장 많은 class를 택해서 결론을 내린다.
Bagging 방법의 한계
앞서 말한 방법만 생각한다면 bagging은 충분히 매력적인 분석 방법으로 보일 수 있으나 이러한 방식에는 치명적인 문제점이 있다. Bagging 으로 tree를 아무리 많이 fitting을 해도 만들어지는 tree 마다 모든 feature 를 전부 다 사용하여 예측하기 때문에 모든 feature를 고려했을 때 상대적으로 중요한 변수는 다른 tree에서도 중요하고, 중요하지 않은 feature는 다른 tree에서도 별로 중요하지 않게 된다. 결국 비슷한 tree만 잔뜩 만들어져서 tree간의 독립성이 떨어지게 된다. 이것은 마치 여론 조사를 할 때 정치적 성향이 비슷한 집단에만 반복적으로 질문을 해서 결론을 내리는 것과도 같다. 다음 포스팅에서는 이러한 단점을 극복한 Random Forest에 대해 설명하고자 한다.
'데이터 사이언스' 카테고리의 다른 글
| 통계기법을 사용한 소음의 정도에 따른 조류의 행동 변화 분석 (2) | 2022.04.19 |
|---|---|
| 비개발자의 언어로 풀어 쓴 API 의 구조와 기능 (2) | 2022.04.18 |
| 중심극한정리를 이용한 가설검정 (0) | 2022.04.13 |
| 머신러닝에서 자주 쓰이는 Random Forest, Boosting (1) | 2022.04.10 |
| Tree-based 머신러닝의 기초개념, 해석 방법 및 주의점 (0) | 2022.04.09 |



