Hyperparameter tuning 이 실패한 경우
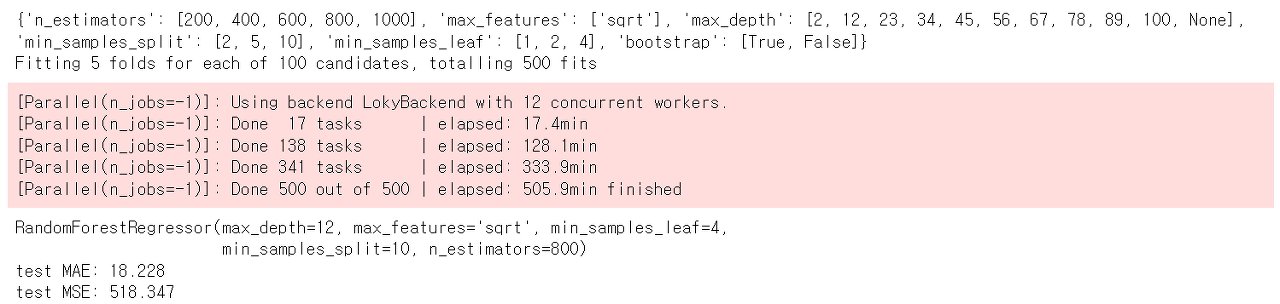
number of estimator 를 200부터 1000까지의 범위로 설정하고, maximum feature의 개수 (하나의 tree model에서 사용될 최대의 feature 수)는 전체 feature의 개수의 square root 가 되도록, 설정했다. 그리고 maximum depth는 2부터 100까지 일정 간격으로 띄워서 자동으로 10개의 숫자가 나오도록 했다. minimum sample split은 무작위로 2, 5, 10 중의 하나가 되도록 하고, min samples leaf 는 1,2,4 중 하나의 숫자를 할당했다. 그리고 boot strap 여부도 무작위로 할것인지, 아니면 하지 않을 것인지를 정하도록 했다. 그리고 5-fold cross validation 과정을 거쳐 어떤 하이퍼파라미터의 조합이 최적이며, 그 때의 오류는 어느정도인지 알아보고자 했다. 그 결과는 매우 절망적이었다. MSE가 518이 나왔는데, 이는 내가 이전에 hyperparameter를 전혀 tuning 하지 않고서도 440 이라는 훨씬 낮은 수치를 얻었기 때문이다. 더군다나 hyperparameter 를 tuning하는데 500분, 약 9시간이 걸렸다는 점 까지 감안하면 hyperparameter를 내가 스스로 tuning 하는 능력이 얼마나 부족한지를 알 수 있었다. 이런 현상은 사실 이전에도 이미 있었는데, 다시 지금 반복될 줄은 몰랐고 그것이 우연의 일치라고만 생각했었다.
hyperparameter tuning 을 manual하게 했을 때의 정확도가 default 값에서보다 더 떨어지는 현상
예전에 다른 프로젝트에서 어떤 생물학적 물질의 녹는 온도를 다양한 feature로 예측하는 작업을 했었는데, 파이썬으로 내가 hyperparameter tuning을 하면 시간이 매우 많이 걸리고 정확도가 매우 떨어지는 반면, R에서 머신러닝 전용 도구를 이용하여 자동으로 hyperparameter tuning을 하면 짧은 시간 안으로 매우 높은 정확도로 예측을 했다. 그래서 나는 그것이 단순히 다른 통계 프로그램간의 차이 때문에 일어났을 것으로만 추측했는데, 지금 다시 이런 현상이 일어나는 것을 고려해보면 내가 manual 하게 hyperparameter tuning 을 하는 능력에 문제가 있음을 알 수 있다. 이를 극복하기 위해서 생각 나는 방법은 내가 manual 하게 setting 한 hyperparameter 와 자동으로 생성되는 default 값의 hyperparameter 간의 차이를 이해하는 것이다. 그리고 가장 중요한 것은 각 hyperparameter 마다의 특성을 이해해야 한다는 것이다. 어떤 모델에서 어떤 hyperparameter 가 가장 중요하며 어떤 범위 내에서 설정을 해야 하는 지 등에 대한 이해가 있어야 할 것이다. 그렇지 않고 나처럼 무작위로 선정하면 매우 비효율적으로 더 낮은 정확도를 얻게 되는 결과를 초래할 수 있다.
hyperparameter tuning의 default값 알아보기
공식 홈페이지에 정리된 Random Forest 함수의 hyperparameter의 기본 값은 다음 과 같다.
number of estimator는 100으로, 내가 설정한 값과 차이가 많이 나지만 기본적으로 이 값은 높을 수록 더 예측 정확도가 높아지므로 이 값이 100을 넘는다면 이를 조절하는 것은 모델예측 정확도를 개선하는데 크게 도움을 주지는 않을 것으로 보인다. internal node에서 분기를 확장하는데 필요한 최소한의 sample 수는 2이며 이것은 이미 무작위로 지정될 수 있는 숫자인 2, 5, 10중 하나를 포함하고 있어 이는 조절하지 않아도 될 것으로 보인다.
maximum depth는 “none”이다. 즉, 분기가 특정 횟수의 제약 없이 자유롭게 확장되다가 더 이상 분기를 나눌 수 없는 조건이 되면 (어떤 node에서 분기를 확장하는데 필요한 최소한의 sample 개수보다 낮은 sample 수가 있는 경우) 그때서야 분기를 확장하는 것을 멈춘다는 것을 의미한다. 이 또한 내가 무작위로 이 옵션도 선정될 수 있도록 해 놓았기 때문에 개선의 여지가 없어보인다. 말단에서의 최소 샘플 수는 기본적으로 1개 이다. 이는 말단 노드에서 요구되는 최소한의 sample 수는 1개 이상이면 된다는 것이다. 이 또한 내가 무작위로 설정한 값인 1,2,4 중 1개이므로 이 또한 개선하지 않아도 되는 부분이다. maximum feature는 이론상으로는 square root가 가장 안정적이라고 하여 그것이 default값일 줄 알았는데, 알고보니 그저 최대값의 제한 없이 사용할 수 있는 모든 최대한의 feature 개수를 최대값으로 설정하는 것이 default였다. 이 부분이 내가 manual 하게 작성한 hyperparameter tuning 조건과 많이 다른 부분으로, 이를 square root가 아닌, 모든 feature 개수로 설정하도록 개선시켜 보는 것이 필요해 보인다.
'데이터 사이언스' 카테고리의 다른 글
| for loop과 fig, ax 사용하여 그림 그리기 (2) | 2022.07.23 |
|---|---|
| 머신러닝 Feature engineering 이 중요한 이유 (1) | 2022.05.20 |
| 머신러닝 모델 적합을 할 때 cross-validation 을 적용한 사례 (3) | 2022.05.15 |
| 머신러닝을 이용한 월급 예측 데이터 분석 포트폴리오 (3) | 2022.05.14 |
| A/B test: 고객의 선호도를 통계적으로 분석하는 방법 (0) | 2022.05.09 |



